
※こちらは、「Amazon ConnectでCX向上!通話記録の文字起こしを自動化するには」の続きになります。
Amazon ConnectでCX向上!通話記録の文字起こしを自動化するには | AWS活用法
Amazon Comprehendを使用した感情分析
顧客対応情報から感情を可視化
感情分析とは、指定されたテキストをAIが自然言語処理によって取り込み、そのテキストの背景にある感情的な考え方を分析することです。
感情分析により、それまで可視化することが出来なかった「テキストの背景にある感情」を、ポジティブ、ナチュラル、ネガティブなどに分類することができるようになります。分析結果をもとに、良い点は継続し悪い点は改善を行うことで、CX向上につなげることができます。
下記の例では、「美味しい」という文言を含んでいる複数のテキストについて、AIは感情を読み取ります。
このような情報の蓄積により、顧客からの評価を感情まで含めて可視化できるようになり、顧客対応品質のブラッシュアップに活用できます。

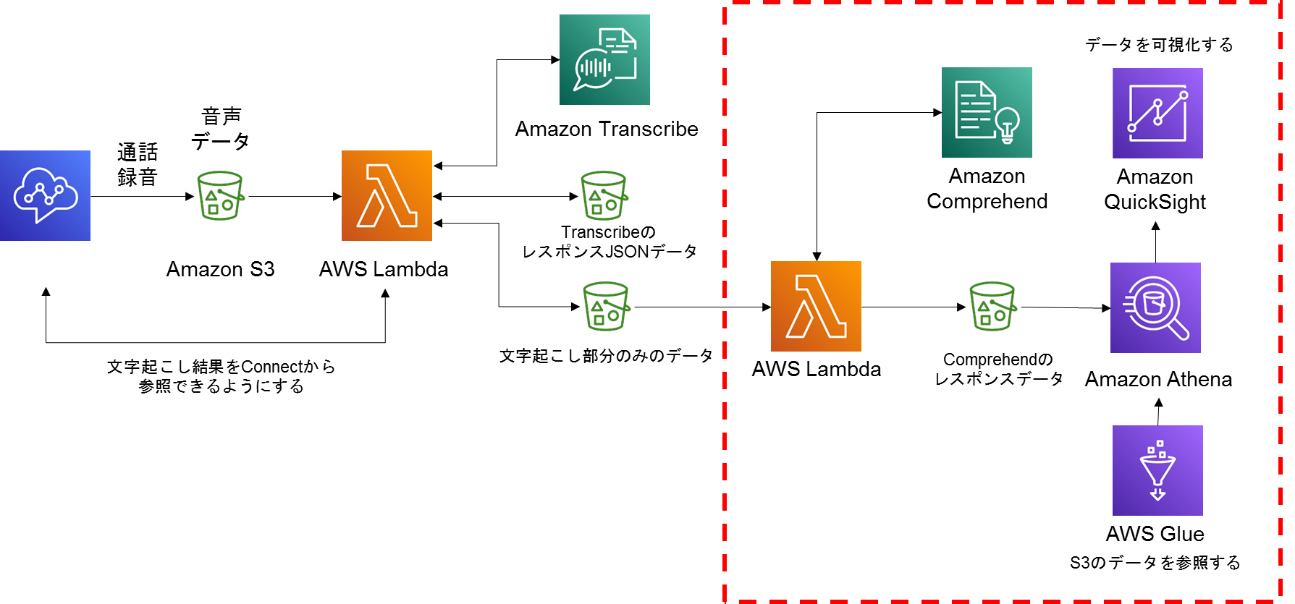
今回の構築範囲と概要
今回は図の赤枠内を構築していきます。
Amazon Comprehend![]() は、音機械学習を使用し、キーフレーズ抽出・感情分析・エンティティ認識などが実行できる自然言語処理(NLP)サービスです。今回は、感情分析を行うためにこの機能を実装します。
は、音機械学習を使用し、キーフレーズ抽出・感情分析・エンティティ認識などが実行できる自然言語処理(NLP)サービスです。今回は、感情分析を行うためにこの機能を実装します。
Amazon Comprehendについては、以下の記事で詳しく紹介しています。ぜひ本記事と併せてご確認ください。
Amazon Comprehendとは? 事例を交えて活用法をわかりやすく解説!| AWS活用法
構築手順
1. Amazon S3バケットを作成
①Amazon Comprehend用のAmazon S3バケットを作成
(1) AWS マネジメントコンソールより、Amazon S3を選択します。Amazon S3のページからバケットの作成をクリックします。

(2) Amazon S3のパラメータを適切に設定し、バケットを作成します。
| バケット名 | 自分の名前+日付_comprehend_1などの分かりやすい名前で作成することをオススメします。後で使用するので、メモをしておくと便利です。 |
|---|---|
| リージョン | Amazon Connectと同じリージョンを選択。 |
| 以降のパラメータ | デフォルトのままでバケットの作成をクリック。 |
![Amazon S3のパラメータを設定し、[バケットを作成]をクリックし、各種事項を設定する。](/white-paper/resource/0416-img-05.png)
2. AWS Lambdaの作成
下記のような内容の処理を実装します。手順の詳細につきましては、お問い合わせいただければご提供いたします。
1.Amazon S3にファイルが置かれたことをトリガーにAWS Lambdaを起動
2.Amazon S3に置かれたJOSNデータを取得しテキストデータに成形
3.Amazon Comprehendを使用して感情分析を実施
4.感情分析結果をAmazon S3に保存
3. AWS Glueでカタログ化
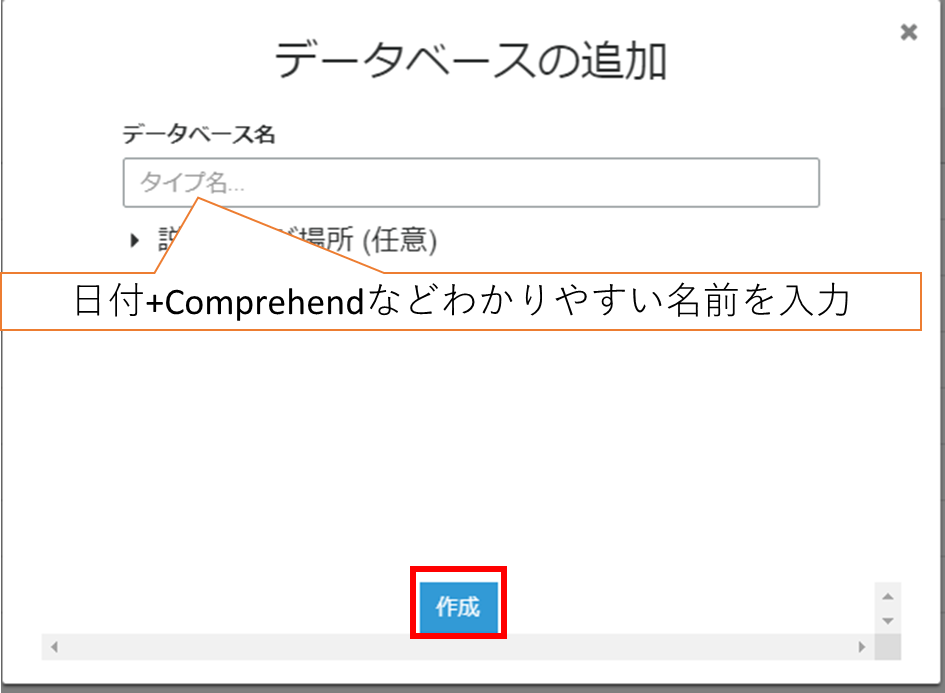
①データベースの追加を行う
(1) AWS マネジメントコンソールより、AWS Glueのページに移動しデータベースの作成をクリックします。

(2) データベース名を入力して作成をクリックします。
| データベース名 | 日付+Comprehendなどわかりやすい名前を入力しましょう。 |
|---|
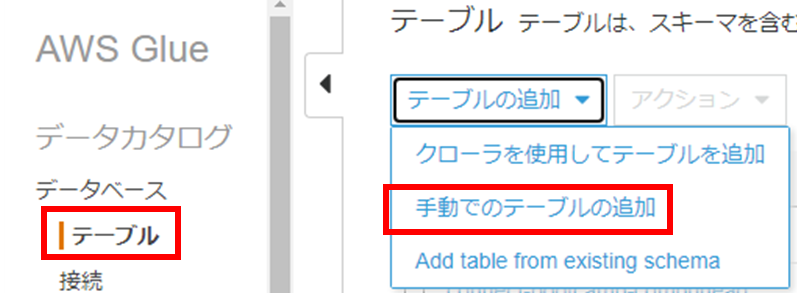
②テーブルの作成
(1) テーブルのタブに移動し、手動でテーブルの追加をクリックします。
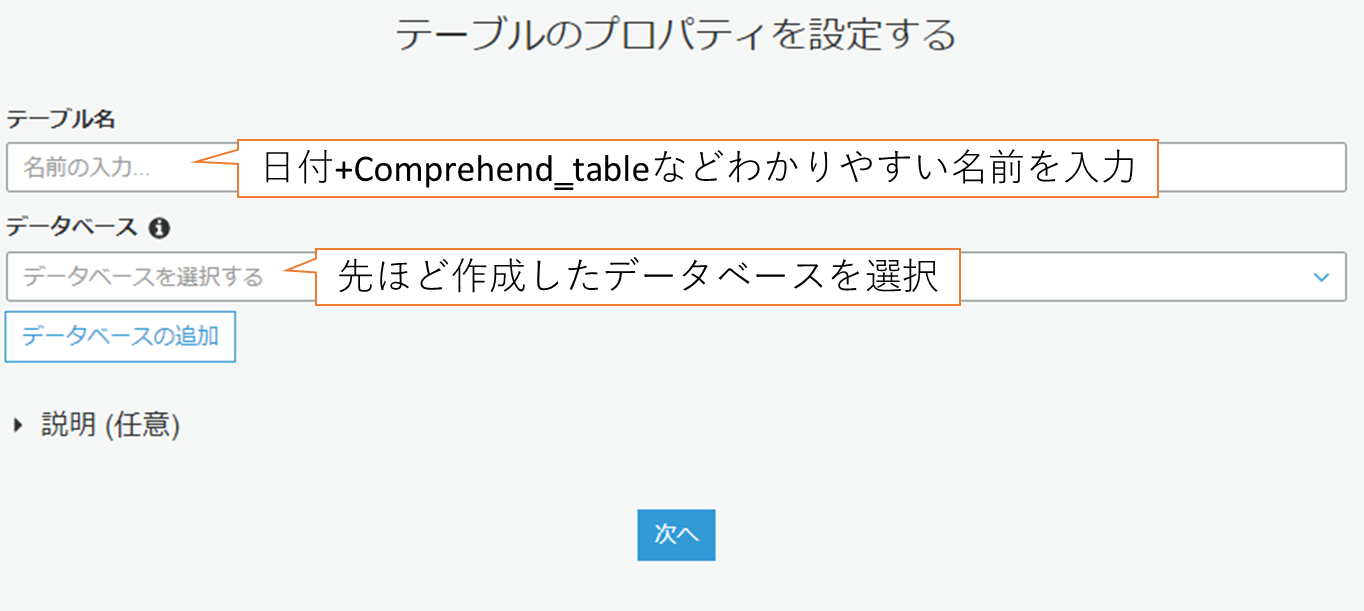
(2) テーブルのプロパティを設定します。
| テーブル名 | 日付+Comprehend_tableなどわかりやすい名前を入力しましょう。 |
|---|---|
| データベース | 先ほど作成したデータベースを選択します。 |
(3) データストアを選択します。
| Select the type of source | S3を選択します。 |
|---|---|
| データの場所 | 自分のアカウントで指定されたパスを選択します。 |
| インクルードパス | 手順1「Amazon S3バケットを作成」で作成したバケットを選択します。 |
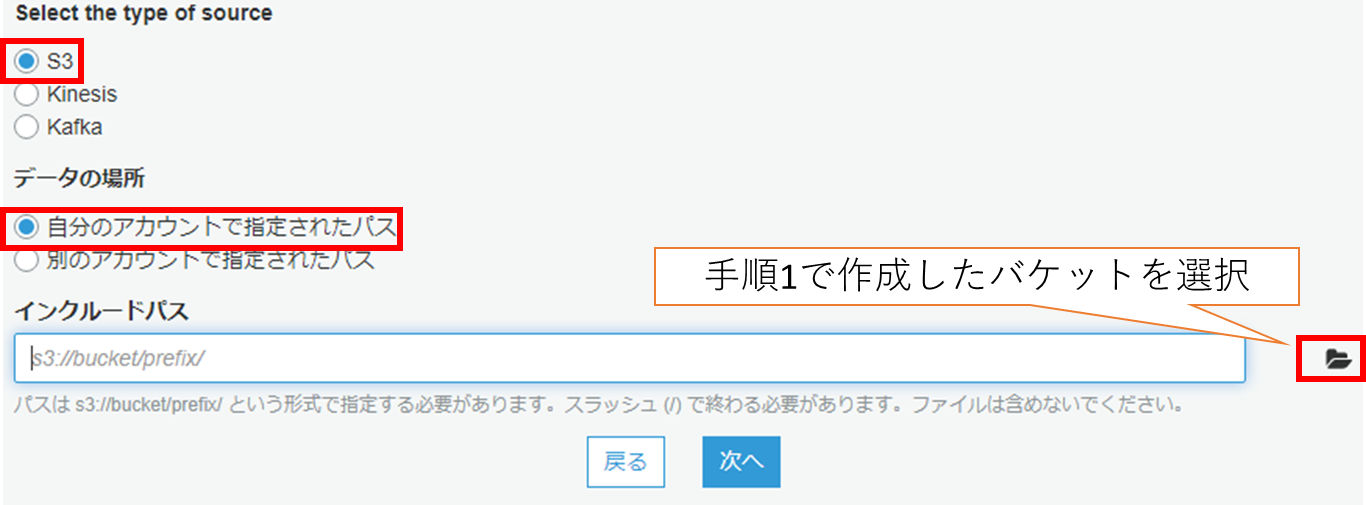
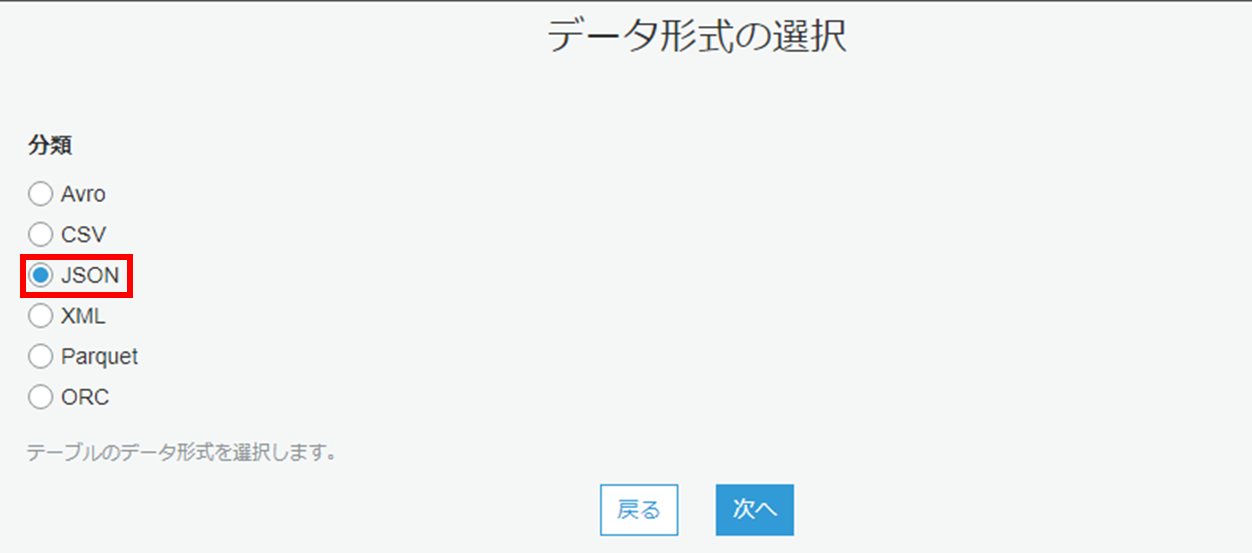
(4) データ形式を選択します。
| 分類 | JSONを選択します。 |
|---|
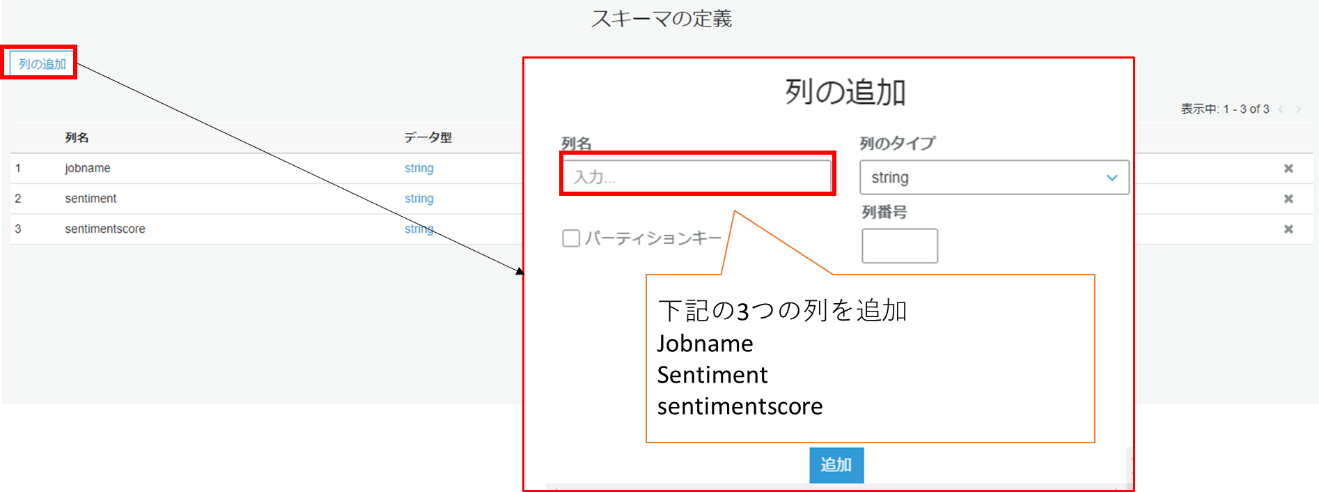
③ スキーマを定義
列の追加をクリック後、列名にてJobname、Sentiment、Sentimentscoreを追加します。
4. Amazon QuickSightで可視化
① Athenaへのアクセスを許可
(1) Amazon QuickSightのコンソールを開き、アクセス管理ページを開きます。リージョンをバージニア北部に変更した後、右上のアカウント箇所をクリックします。
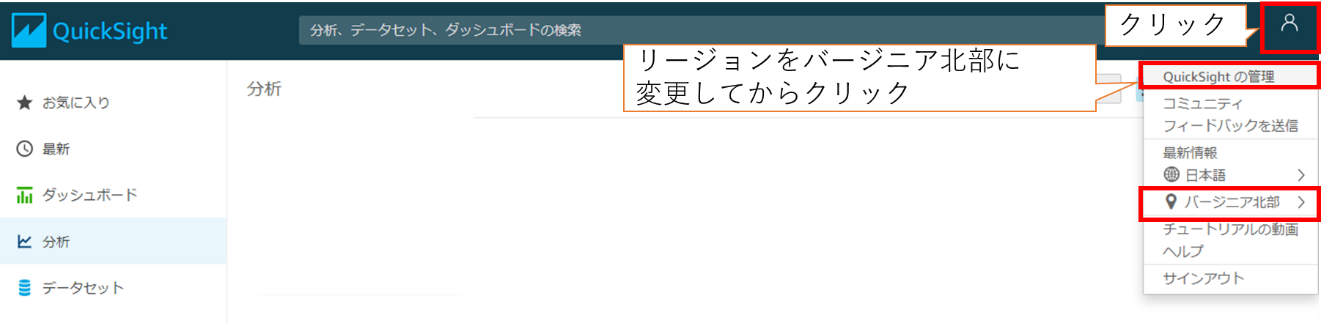
(2) セキュリティとアクセス権限をクリック後、AWSサービスへのアクセス権を追加するをクリックします。

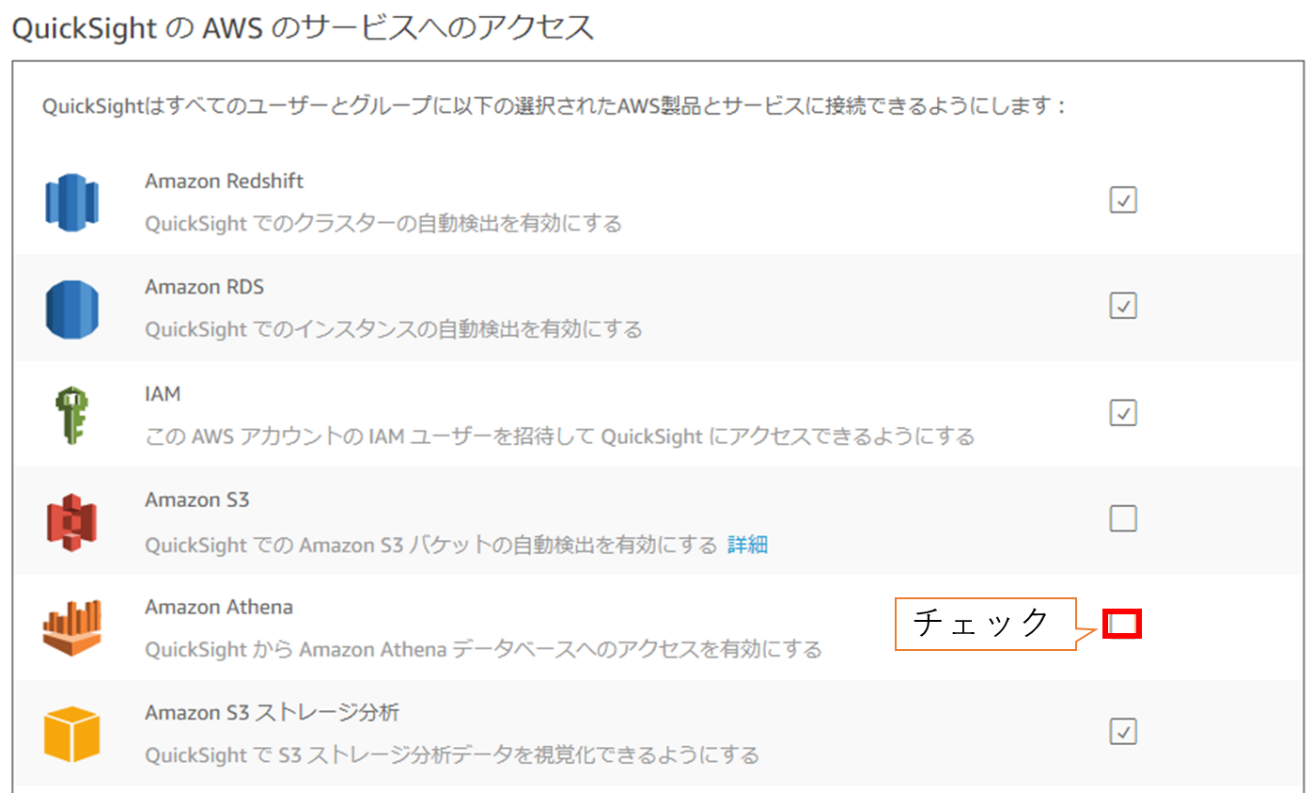
(3) Amazon Athenaにチェックを入れ、次へをクリックします。
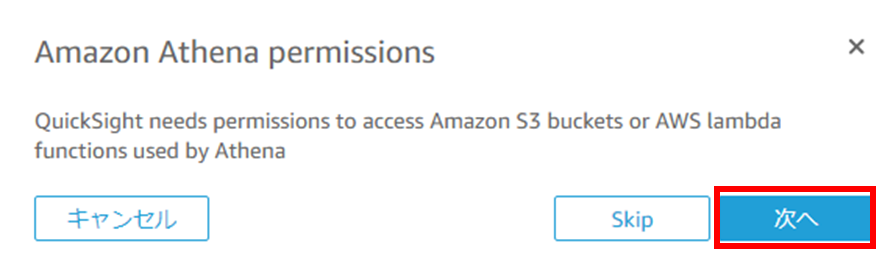
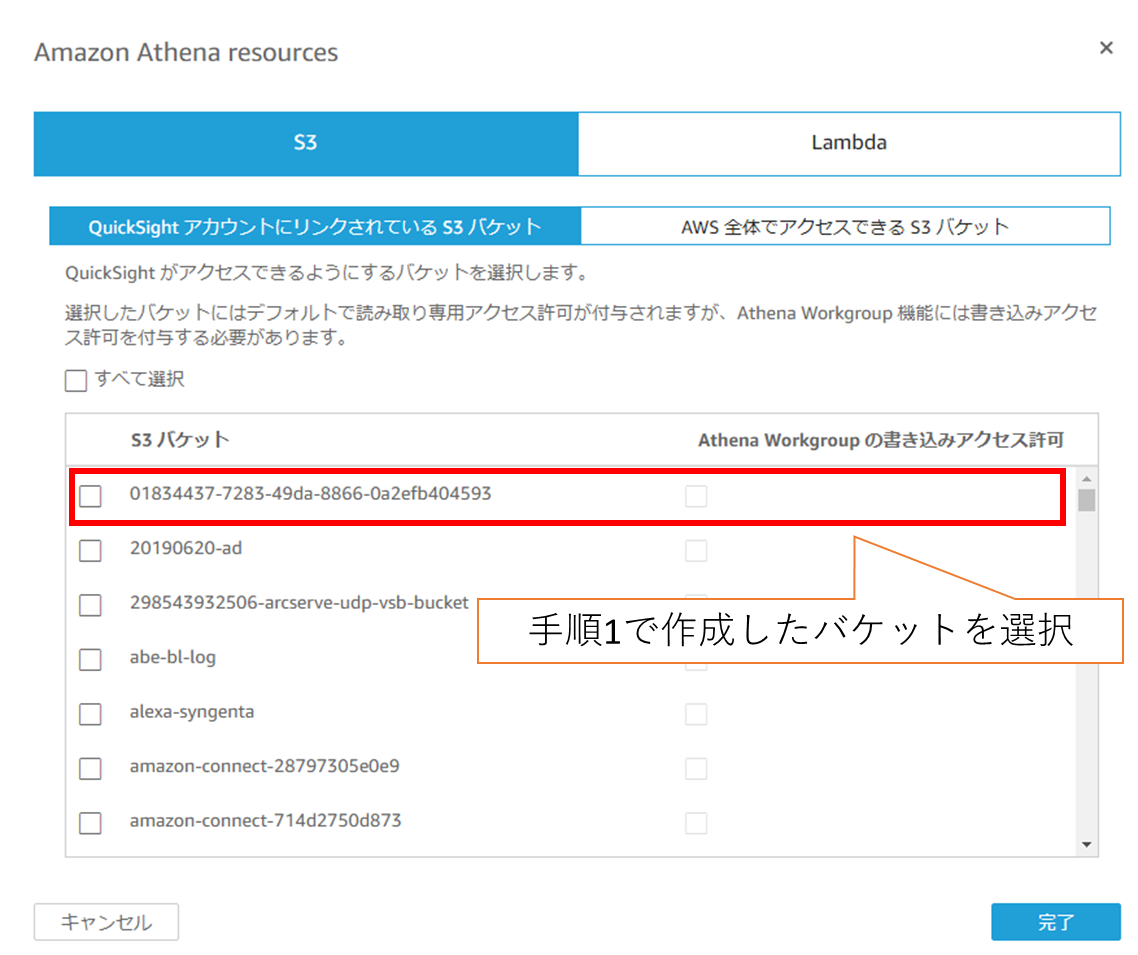
(4) S3バケットへのアクセス権を付与します。
この時、手順1「Amazon S3バケットを作成」で作成したバケットを選択してください。
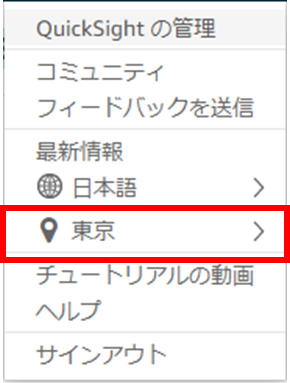
(5) 元のリージョンに戻す
② データセットを登録
(1) データセットより、新しいデータセットをクリックします。

(2) Athenaを選択します。
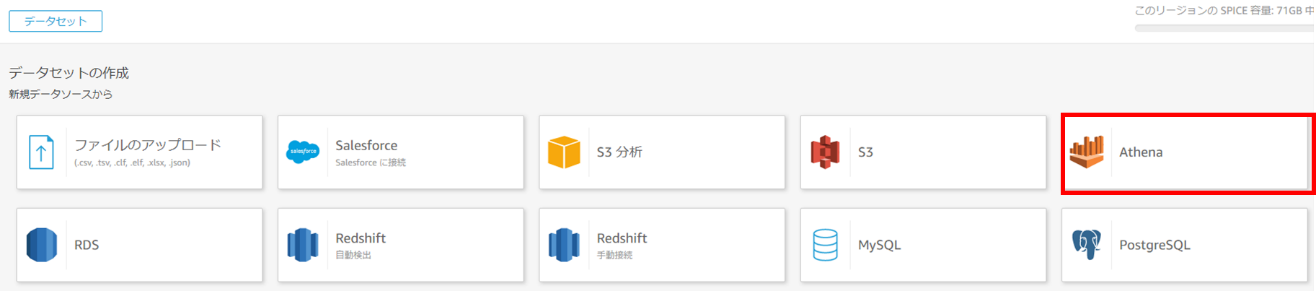
(3) データソース名、ワークグループを選択します。
| データベース名 | 日付+Comprehendなどわかりやすい名前を入力しましょう。 |
|---|---|
| Athenaワークグループ | primaryを選択します。 |
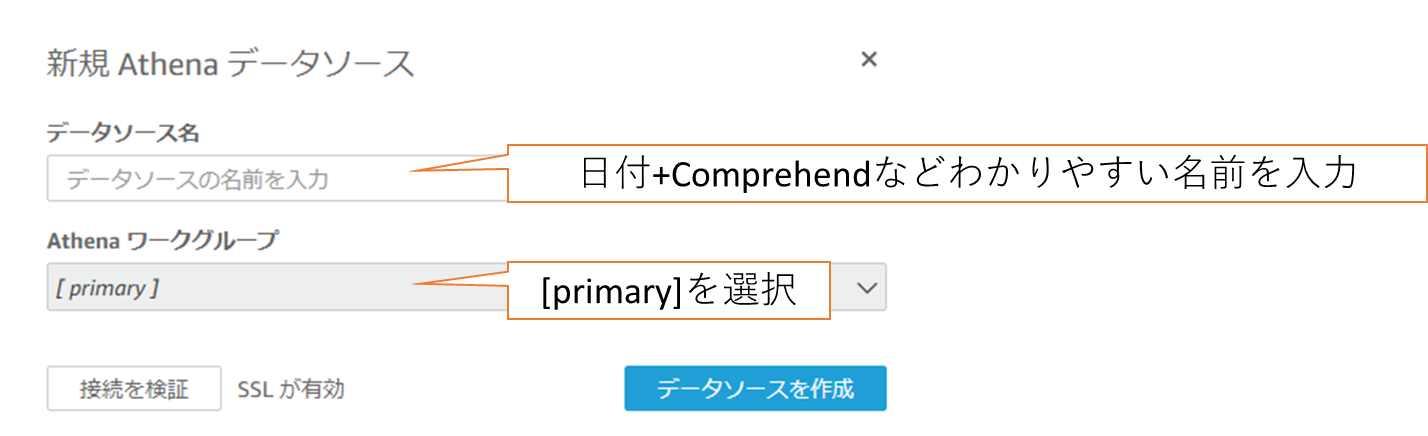
③ テーブルの選択
| Catalog | AwsDataCatalogを選択します。 |
|---|---|
| データベース | 手順3「AWS Glueでカタログ化」で作成したデータベース名を選択します。 |
| テーブル | 手順3「AWS Glueでカタログ化」で作成したテーブル名を選択します。 |
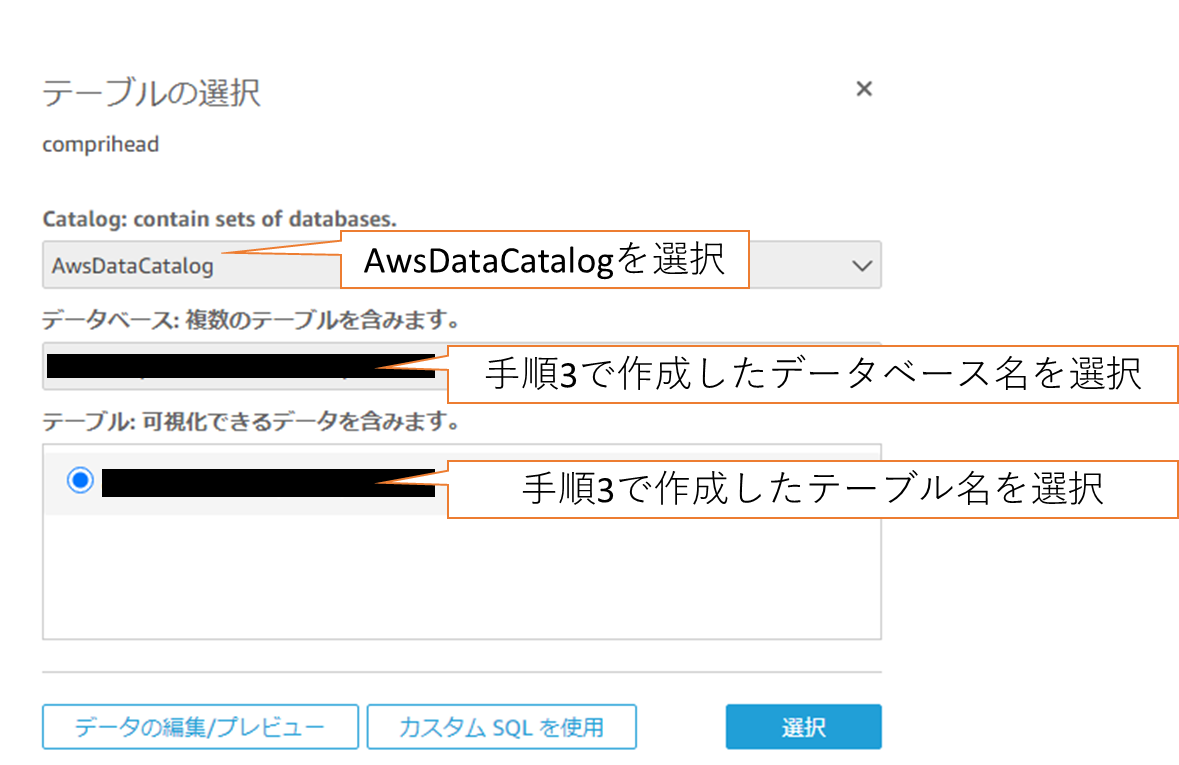
④ データセットの作成
デフォルト設定のまま、Visualizeをクリックします。
⑤ データセットを編集
(1) データセットより、作成したデータセットをクリックします。

(2) データセットの編集をクリックします。
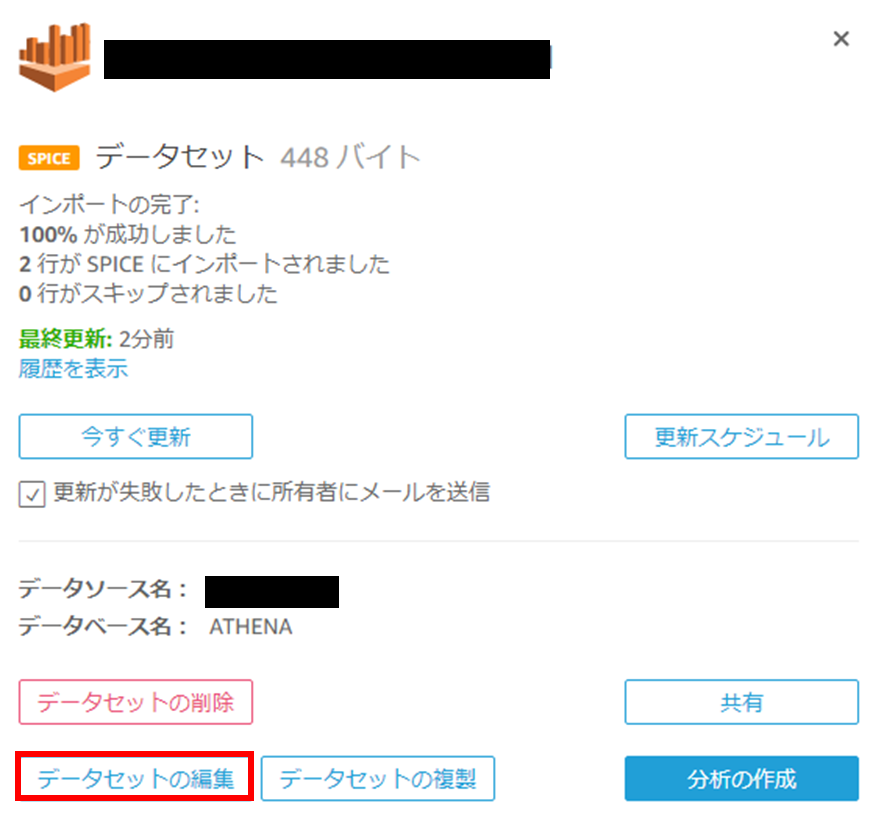
(3) 計算フィールドの追加をクリックします。
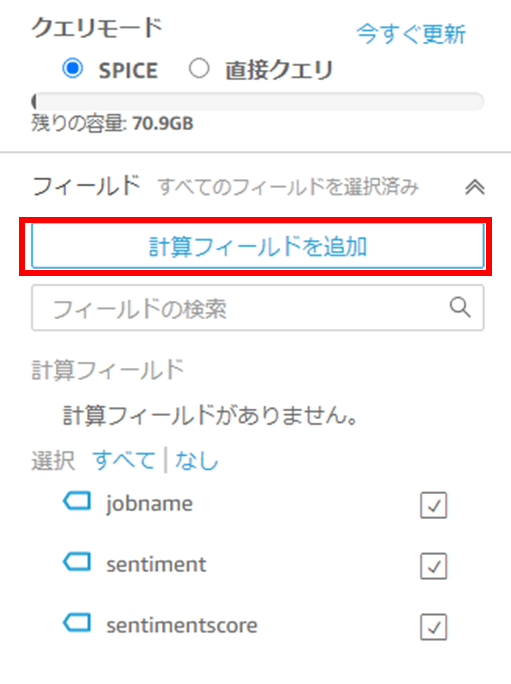
(4) 4つの計算フィールドを追加します。
| 名称 | 計算式 |
|---|---|
| positive | parseDecimal(parseJson(sentimentscore,'$.positive')) |
| negative | parseDecimal(parseJson(sentimentscore,'$.negative')) |
| neutral | parseDecimal(parseJson(sentimentscore,'$.neutral')) |
| mixed | parseDecimal(parseJson(sentimentscore,'$.mixed')) |

(5) 保存をクリックします。

動作確認手順
① 結果確認
(1) データセットのページから、データセットのプロパティを開きデータの更新を行います。今すぐ更新をクリックします。
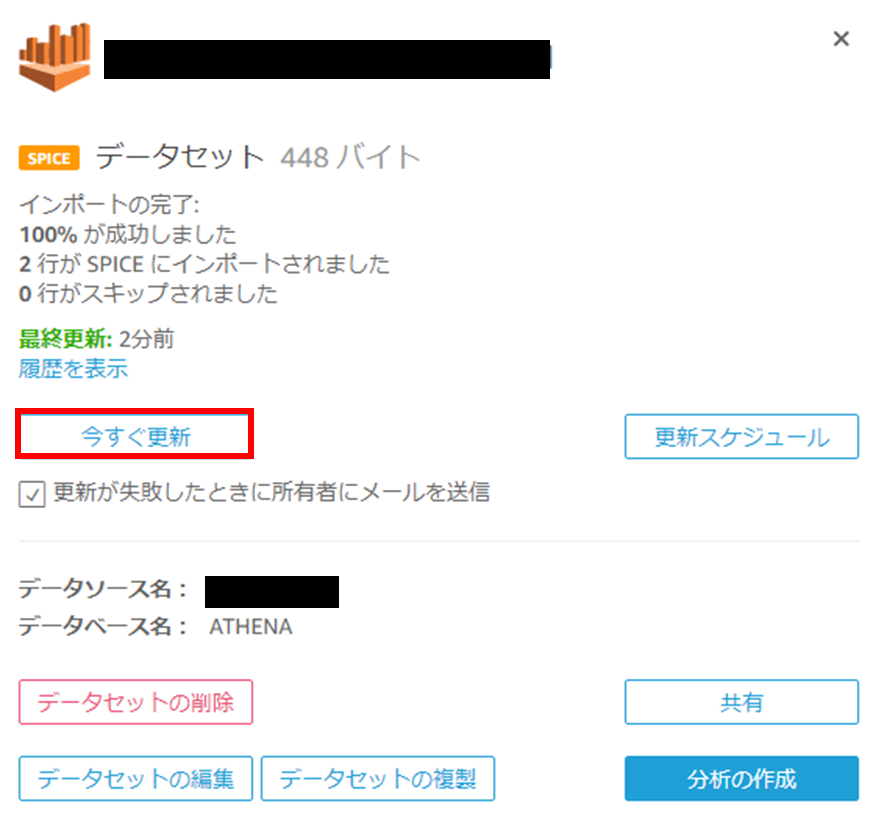
(2) 更新をクリックします。
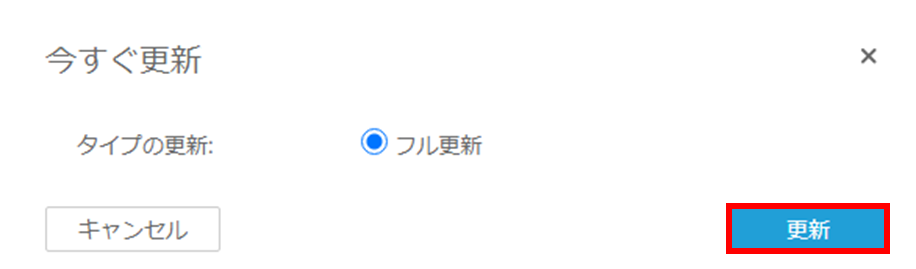
(3) 分析の作成をクリックします。
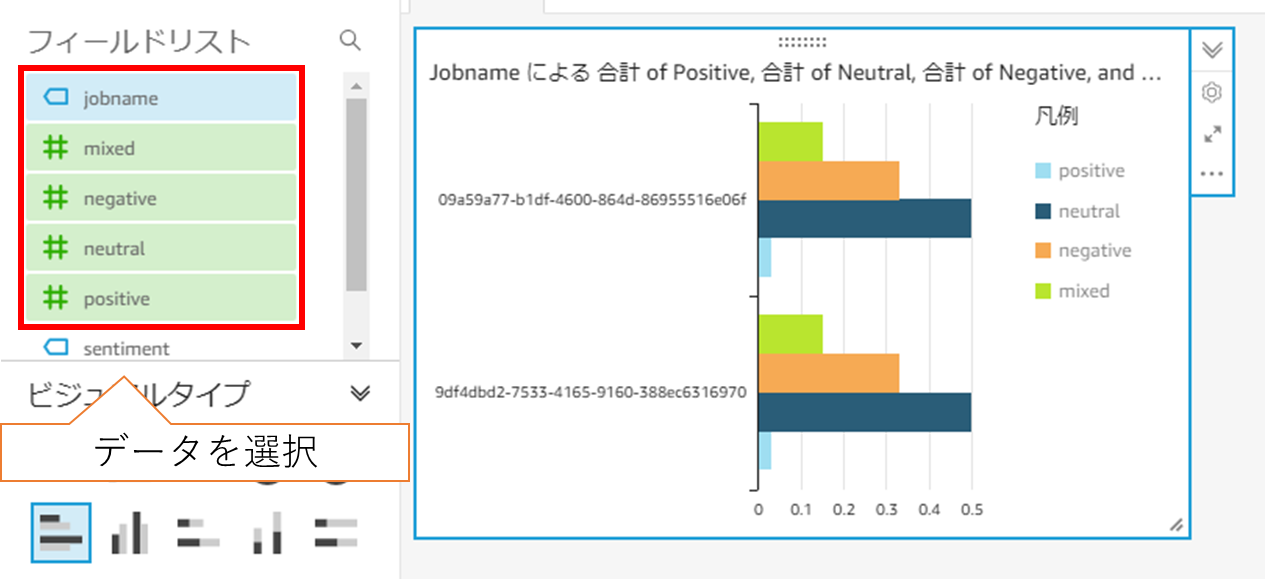
(4) 分析結果を確認します。これで、感情分析の完了です。
まとめ
この記事では、Amazon ConnectとAmazon Comprehendを活用し、通話データの感情分析を実装しました。
今回は1つの通話データで感情分析を行いましたが、時間毎に区切ることで感情の変化も可視化して分析に利用することが可能です。
今回の記事の技術や、AWS導入にご興味がある方は、是非お問い合わせ![]() ください。
ください。
関連サービス

おすすめ記事
-
2024.03.26
サーバーレス活用例|iPhoneとiBeaconで自動車通過チェックシステムを作ってみた -AWS LambdaとBLEで作るサーバーレスな通過記録アプリ-

-
2024.02.06
AWS Lambda活用ガイド|活用事例から学ぶAWS Lambdaの特性や注意点

-
2023.12.28
展示物解説アプリをiPhoneとiBeaconで作ってみた -AWS LambdaとBLEで作るサーバーレスな接近検知アプリ-

-
2023.05.23
AWSで実現するサーバーレスとは? 向き不向き、導入の成功ポイントを解説

-
2023.02.27
サーバーレスの時代? AWS Lambdaを活用した、サーバーレスアーキテクチャのシステム開発のすすめ
